



Transaction monitoring rules are the backbone of an AML compliance program, but they are not a “set and forget” component. Financial criminals constantly adapt, and business activities evolve, meaning even well-designed rules can become inefficient or imprecise over time. Many institutions using legacy rule-based systems suffer false-positive rates above 90%, which overwhelms compliance teams with noise and risks letting true threats slip through. To combat this, compliance officers, AML analysts, and risk managers must continuously tune and refine their monitoring rules. By iteratively improving rules’ precision and performance, fincrime teams can dramatically reduce false alerts while sharpening their detection of suspicious activity. This article provides an in-depth, implementation-level guide on how to achieve that continuous tuning, using modern tools like rule simulation, shadow rules, and AI recommendations to optimize your transaction monitoring program safely and effectively.
Why Continuous Rule Tuning Matters
Tuning transaction monitoring rules is essential for maintaining an effective compliance program. Overly broad rules can inundate analysts with benign alerts (false positives), while overly narrow or outdated rules may miss real suspicious patterns (false negatives). Continuous refinement strikes the right balance. Monitoring key performance indicators (KPIs) of your AML program will quickly reveal when rules need adjustment. For example, a sudden spike in alert volume might indicate emerging risks or an overly sensitive rule, whereas a drop in alerts could mean rules are too restrictive and missing activity. Similarly, a persistently high false-positive rate (e.g. 95%+ alerts being cleared as legitimate) is a clear signal that your rules are not finely tuned. In fact, if only a tiny fraction of alerts ever lead to a Suspicious Activity Report (SAR), it means the system is far too noisy. On the other hand, if certain typologies (suspicious patterns) never trigger any alerts, you may have a blind spot in your rules.
The goal of continuous tuning is to ensure you’re flagging fewer but higher-quality alerts over time. By regularly analyzing alert trends and outcomes, compliance teams can decide where to recalibrate thresholds or logic. Modern AI-powered AML platforms like Flagright make this process data-driven and efficient with built-in analytics dashboards. The software acts as a control panel aggregating all your compliance metrics, so you can spot issues at a glance. Instead of manually crunching numbers, teams get instant visibility into alert volumes, false-positive rates, SAR conversion rates, and other KPIs via dashboards. These insights highlight underperforming rules that need attention. In the next sections, we’ll walk through a cycle of steps to tune your rules continuously: identifying which rules to improve, testing changes with simulations, trialing them in production with shadow mode, monitoring the outcomes, and leveraging AI recommendations to optimize further.
Identifying Underperforming Rules
The first step is to pinpoint which monitoring rules are underperforming. “Underperforming” could mean a rule is too sensitive (triggering many alerts that turn out false) or not sensitive enough (rarely triggering, potentially missing risk). Here’s how to identify these cases using data:
- High False-Positive Rates: Review the false-positive rate per rule (the percentage of that rule’s alerts that were cleared with no issue). A consistently high false-positive rate, e.g. 90%+ of alerts from a rule are false alarms indicates the rule’s conditions or thresholds are not well-calibrated. Such a rule is wasting investigator time and should be a top candidate for tuning. In practice, if Rule A generated 100 alerts last month and none led to findings, its precision is low. An excessively high false-positive rate signals your rules need refinement (through better segmentation or threshold tuning).
- Low Alert Conversion (Few True Positives): Examine what proportion of a rule’s alerts result in SAR filings or truly suspicious findings. If out of hundreds of alerts only a negligible number turn into reportable cases, the rule may be too broad. For context, many banks find less than ~5% of alerts ultimately warrant SARs under legacy systems. If your conversion is near 0%, it’s a sign the rule is generating “junk” alerts.
- Disproportionate Alert Volume: Use your analytics dashboard to watch alert trends. A rule that suddenly spikes in volume might be reacting to a trend (or misconfiguration) that needs investigation. Conversely, a rule that never or hardly ever triggers might have thresholds set so high (or logic so narrow) that it’s not effective. Both scenarios warrant a review.
- Known Risk Typologies Not Triggering: Cross-check your rules against known typologies or regulatory red flags. If, for example, you have a rule for structured deposits or rapid inflows/outflows and yet you’ve observed cases of structuring that went unflagged, then that rule might be too lax. A telltale sign is if certain types of suspicious behavior are known to occur in your business but your system shows zero alerts in that category. That indicates a blind spot; perhaps thresholds need lowering or new sub-conditions added to catch those patterns.
Flagright’s platform simplifies this identification stage by providing built-in analytics and reports. Compliance teams can pull up dashboards showing each rule’s alert count, how many cases or SARs it led to, and false-positive ratios. This eliminates guesswork. By reviewing these metrics regularly (many teams do it weekly or monthly), you can prioritize which rule to tune first.
Using Rule Simulation to Test Changes
Once you've identified a rule that needs improvement, say, a threshold is too low leading to too many false hits, the next step is to test your proposed rule changes using historical data. This is where rule simulation (also known as backtesting) comes in. A rule simulator lets you answer “What if?” questions safely, before touching production.
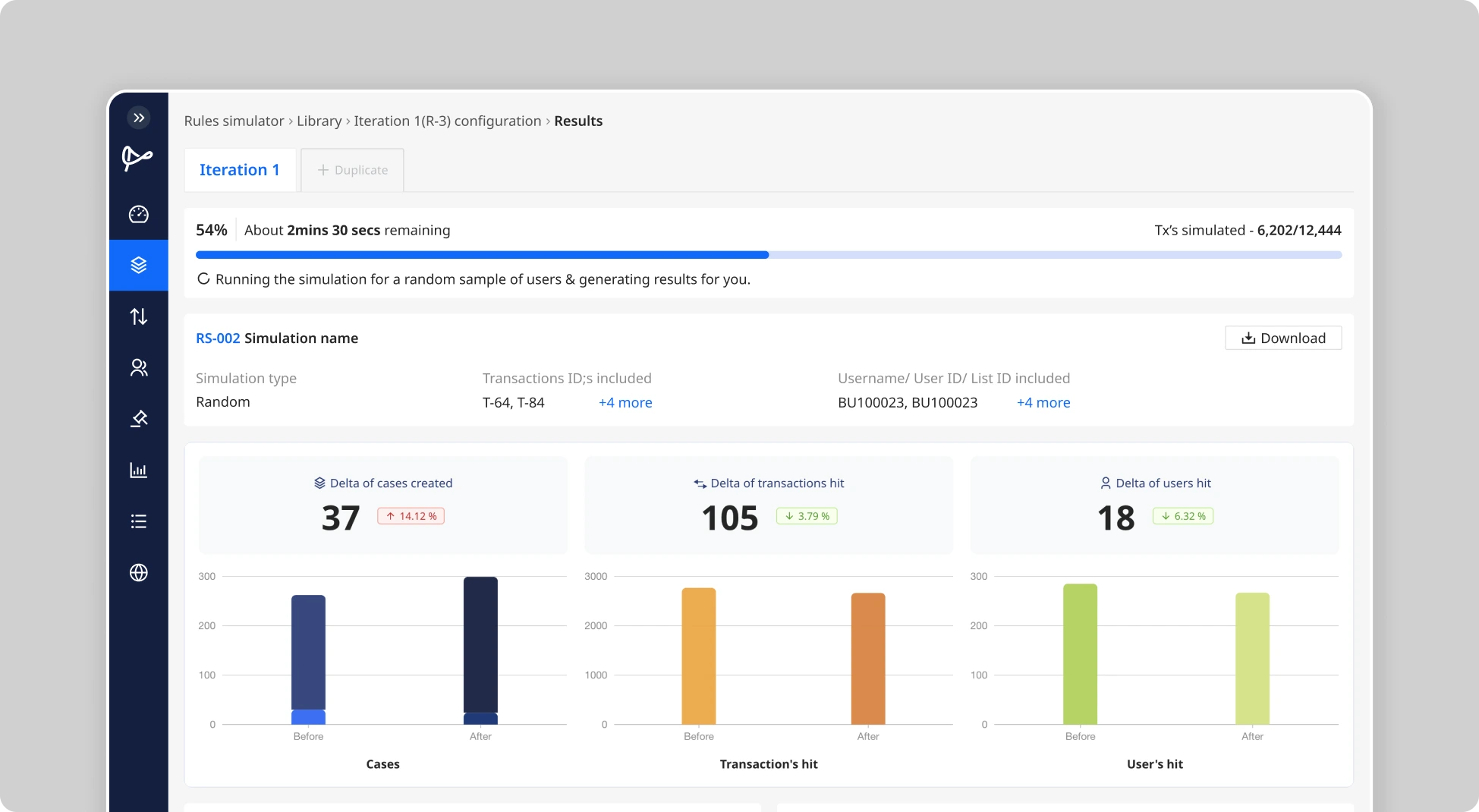
How Rule Simulation Works
Flagright’s rule simulation tool allows you to run any rule (new or modified) against a set of past transactions to see how it would have performed. You can take months of historical transaction data and apply the adjusted rule logic to it as if that rule had been active then. The simulator will output metrics like how many alerts the rule would have triggered on that data, which transactions/users would have been flagged, and even the projected false-positive rate if you have labels for which alerts were genuine. Crucially, this is all done in a sandbox environment, it does not affect your live systems or create any actual alerts/cases.
Practical Guidance for Simulation
- Adjust Rule Parameters: In your no-code rule builder, make the intended change. For example, if an AML rule currently flags any transaction above $5,000, you might test raising the threshold to $7,500; or if a rule looks at more than 3 transfers in a day, you might try requiring more than 5 transfers, etc. You can also test adding filters (like excluding certain low-risk customer segments or geographies).
- Select Historical Dataset: Choose a relevant historical period for backtesting. It’s wise to use a sufficiently large and recent dataset (e.g., last 3 months of transactions) so that you have enough cases to evaluate. If you’re targeting a specific typology (say, bursts of activity at month-end), ensure the dataset covers that scenario.
- Run the Simulation: Using Flagright’s simulator, run the rule on the historical data with one click. The system will quickly evaluate every past transaction in that set against the new rule conditions. For example, if you wonder how a new structuring rule would have performed, you can apply it to Q1’s transactions and instantly see if it would have caught incidents that occurred and how many alerts it would have generated.
- Analyze the Results: Examine the simulation output. Key things to look for include: Alert count; Did the change dramatically cut down the number of alerts (good for reducing noise, but ensure you didn't remove too many real positives)? False-positive reduction; If you have labeled past alerts, see how the ratio improves. Coverage of incidents; Check if known suspicious events in the historical data were still detected under the new parameters. For instance, if raising a threshold from $5k to $7.5k eliminates 30% of alerts and those were all low-risk ones (false positives), and all the truly suspicious cases were still caught, that's a favorable outcome.
- Iterate if Needed: Often you may tweak and simulate multiple times to hone in on the optimal setting. The simulator enables iterative tuning: adjust the threshold a bit more, add another condition, or test a narrower time window, then run again to compare. This trial-and-error process is fast and safe, allowing you to fine-tune without any disruption. According to Flagright, teams commonly adjust and test a few variations before finalizing a rule change. Using simulation, you can keep adjusting parameters until the balance between sensitivity and specificity feels right, finding the sweet spot where the rule catches the bad actors but generates minimal noise.
By simulating rule changes on historical data, you gain confidence in the impact of your tweaks. It flips the traditional approach on its head, rather than deploying a change and then discovering it was too aggressive or not aggressive enough, you get a preview of outcomes in advance. This data-driven testing prevents the classic “tweak and pray” scenario. As a result, when you do proceed to implement the change in live monitoring, you already know roughly what to expect (e.g. alert volume should drop by 20% and no real cases will be missed). In short, simulation de-risks the tuning process by letting you fine-tune accuracy, reduce false positives, and plug coverage gaps before anything goes live.
Trialing Changes in Shadow Mode (Safe Live Testing)
After you've identified a promising rule adjustment through simulation, the next step is to validate the rule in real-time operations without causing disruptions. This is achieved via Shadow Rules, one of Flagright’s most powerful capabilities for safe rule tuning. A shadow rule is essentially a rule running in “silent mode” alongside your live rules. It processes all incoming transactions and logs would-be alerts without actually raising them to analysts or blocking transactions. This allows you to observe how the rule behaves on live data, in parallel, without any risk.
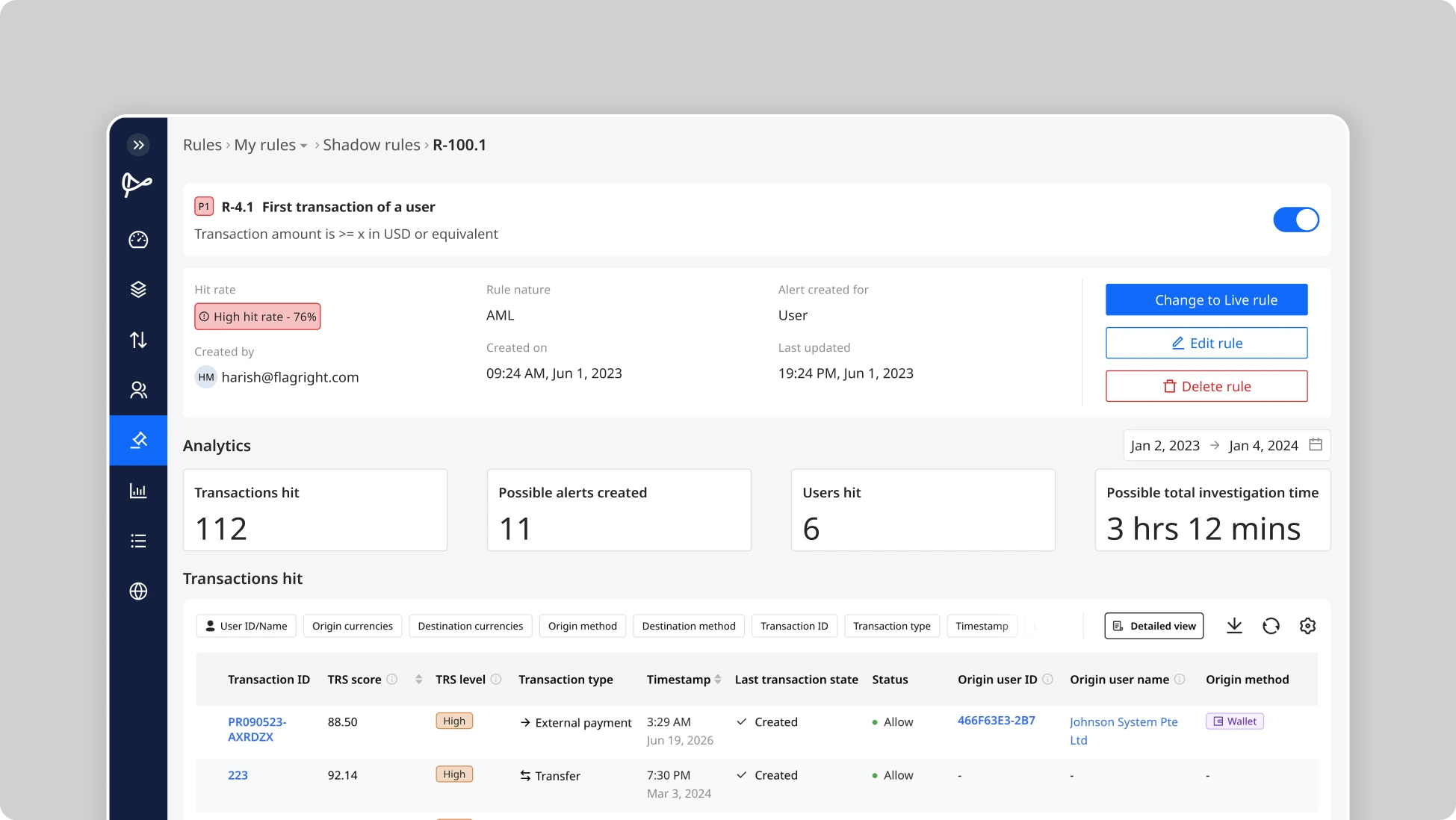
Using Shadow Rules in Practice
- Deploy as Shadow: Instead of immediately activating your tuned rule as a normal alerting rule, you set its status to “shadow”. It will receive the streaming live transaction feed just like other rules, but any alert it flags is held internally (not sent to your case queue). In Flagright’s system, this is as simple as a toggle when creating or editing a rule.
- Run Shadow Period: Let the shadow rule run for a defined trial period, many teams choose about one week of monitoring, though it could be a few days or a full transaction cycle (e.g. a month) depending on volume. During this phase, closely watch the shadow rule’s metrics. The platform will show how many alerts would have been generated by the rule, what the details of those alerts are (e.g. who would be flagged and why), and other stats like what percentage of total transactions it’s impacting.
- Evaluate Performance: Treat this like a pilot test. Did the shadow rule behave as expected on live data? For example, if your simulation predicted a ~20% alert reduction, does the shadow rule’s count confirm a similar drop? Examine a sample of the shadow alerts: are they legitimate hits (would you consider them worth investigating) or do they still include obvious false positives that slipped through? Also note if the rule missed anything: since your normal rules are still running, you can compare; did any suspicious incident get caught by another rule but not by the shadow rule (indicating the new logic might be too lenient)? Shadow mode provides a reality check in real-time. Compliance teams can use this feedback to tweak the rule further before fully deploying. In fact, it’s common to adjust a shadow rule’s parameters mid-test and continue running it, if initial shadow results show room for improvement.
- Iterate and Confirm: If the shadow results are not satisfactory (e.g., it still shows too many alerts), refine the rule and keep it in shadow for another cycle. Many Flagright clients test on average three iterations of a rule in shadow mode before finalizing it live. This iterative approach ensures that by the time you flip the rule to active, it has been battle-tested under real conditions. On the other hand, if the shadow performance looks good, false positives way down and no obvious misses, it’s a green light to promote the rule to live production.
Why Shadow Rules Are Game-Changing
In traditional systems, making a rule change was risky because a misconfiguration could unleash a flood of alerts or inadvertently leave a gap in coverage. Shadow rules eliminate that risk by mitigating misconfiguration impact entirely. You can see exactly what would happen, before it happens. This means no more unpleasant surprises like hundreds of bogus alerts overwhelming the team or, worse, halting customer transactions erroneously. Instead of firefighting after a bad rule goes live, compliance teams catch and correct issues in a safe environment. As a best practice, roughly 65% of all new or modified rules are now tested in shadow mode by Flagright’s clients before going live, a testament to how integral this step has become for risk-aware rule tuning.
In summary, shadow rules allow you to trial new or adjusted rules in production without any disruption. You validate the rule’s real-time behavior, ensuring it meets regulatory standards and doesn’t overwhelm analysts all while your operations continue normally. By the end of the shadow period, you have concrete evidence that the rule is calibrated correctly (or additional adjustments to make). When you finally deploy it fully, you and your team can be confident in its performance. This dramatically minimizes false positives and avoids “surprises”, letting your team focus on real threats rather than cleaning up avoidable alert messes.
Monitoring Alert Performance with Analytics
Tuning transaction monitoring rules is an ongoing cycle. After deploying rule changes (with all the careful simulation and shadow testing beforehand), your job is to monitor the outcomes and verify improvements. This is where continuous analytics come into play. You’ll want to measure whether the tweaks are delivering the expected results and catch any new issues that arise. Flagright’s platform provides comprehensive, real-time analytics to make this monitoring straightforward.
Key actions and metrics to monitor after rule changes include:
- Track False-Positive Rate and Alert Volume (Post-Tuning): Did the false-positive rate for that rule drop to a more acceptable range after the change? For instance, if Rule A was 95% false positives and your tuning aimed to cut noise, check the new false-positive percentage in the days and weeks after going live. You should see a downward trend. Also review overall alert volume, both for that specific rule and in aggregate, to ensure it aligns with expectations. A well-tuned rule should produce fewer alerts, focusing on the more suspicious outliers. If you tuned multiple rules at once, the total alert load on analysts should also go down, improving productivity.
- Review True Positives and Misses: Quality is as important as quantity. Confirm that any real suspicious behaviors are still being caught. One way to do this is by reviewing recent cases or SARs: are they still being triggered appropriately? Another is leveraging any quality assurance processes (some teams review a sample of closed alerts to double-check nothing was wrongly cleared). If something slipped through that the old rule would have caught, that’s a red flag that you might have overtuned (too strict). However, if you see that nearly every alert coming through now is meaningful, that’s a strong sign of success, your precision is up.
- Use Dashboards and Reports: Rather than manually compiling stats, use the compliance dashboard to your advantage. Flagright’s built-in dashboards update in real time with metrics like alert counts, average handling time, investigator workload, etc.. You can often set up specific widgets or reports, for example: “Alerts triggered by Rule A - last 30 days” or “False-positive rate by rule - this month vs last month.” These visualizations let you see the impact of tuning at a glance. If a chart shows that alerts from Rule A dropped from 100 per week to 20 per week after the change, and the false-positive rate for that rule went from 90% to 50%, those are clear indicators of improvement. Monitoring these trends over time also helps you demonstrate the value of tuning efforts to management and regulators (many compliance teams present such before-and-after metrics in audit meetings to show proactive improvement).
- Identify Next Tuning Opportunities: Continuous monitoring will likely reveal other rules that now stand out as underperformers, restarting the cycle. Perhaps after fixing Rule A, you notice Rule B is now the highest contributor to false alerts, or the business introduced a new product and the related rule isn't calibrated yet. Regularly scheduled reviews of the analytics (some teams do quarterly comprehensive rule performance reviews) will ensure you keep picking off the next tuning target. The idea is to embed continuous improvement into your compliance operations, always using the latest data to inform where to focus next. With an analytics console that centralizes all this information, you can easily compare rules and spot anomalies.
- Report and Celebrate Improvements: It’s worth noting the positive outcomes of tuning. For example, if your false-positive rate system-wide was 90% last quarter and through diligent tuning it’s now 70%, that’s a huge efficiency gain; investigators can now spend much more time on real issues. Internally, such wins can be translated into saved analyst hours, faster case resolution times, and potentially cost savings. Externally, regulators will be pleased to see a metric-driven approach to lowering noise and improving the signal in your AML program. Keeping an eye on metrics like SAR conversion rate (which should rise as false positives fall) and alert handling times (which often improve when volume drops) will help you quantify the benefits of your tuning approach.
In essence, monitoring alert performance is about creating a feedback loop. You’ve tuned the rules, now you verify, through data, that the tuning worked as intended. The built-in analytics in modern platforms remove the heavy lifting from this verification step, providing instant feedback. If something’s not right, you’ll see it and can respond quickly (perhaps by reverting a change or doing another round of simulation). If everything looks good, you move on to the next improvement. This continuous monitoring and adjustment cycle is what keeps your transaction monitoring program lean, effective, and responsive to change.
Applying AI Recommendations for Ongoing Optimization
Thus far, we’ve focused on the team-driven process of identifying and tuning rules. Another powerful dimension to continuous improvement is AI-driven recommendations. Flagright’s platform comes equipped with AI features that analyze your data and alert patterns to suggest rule changes or new rules you might not have considered. This is like having a smart assistant that constantly scans for optimization opportunities in the background.
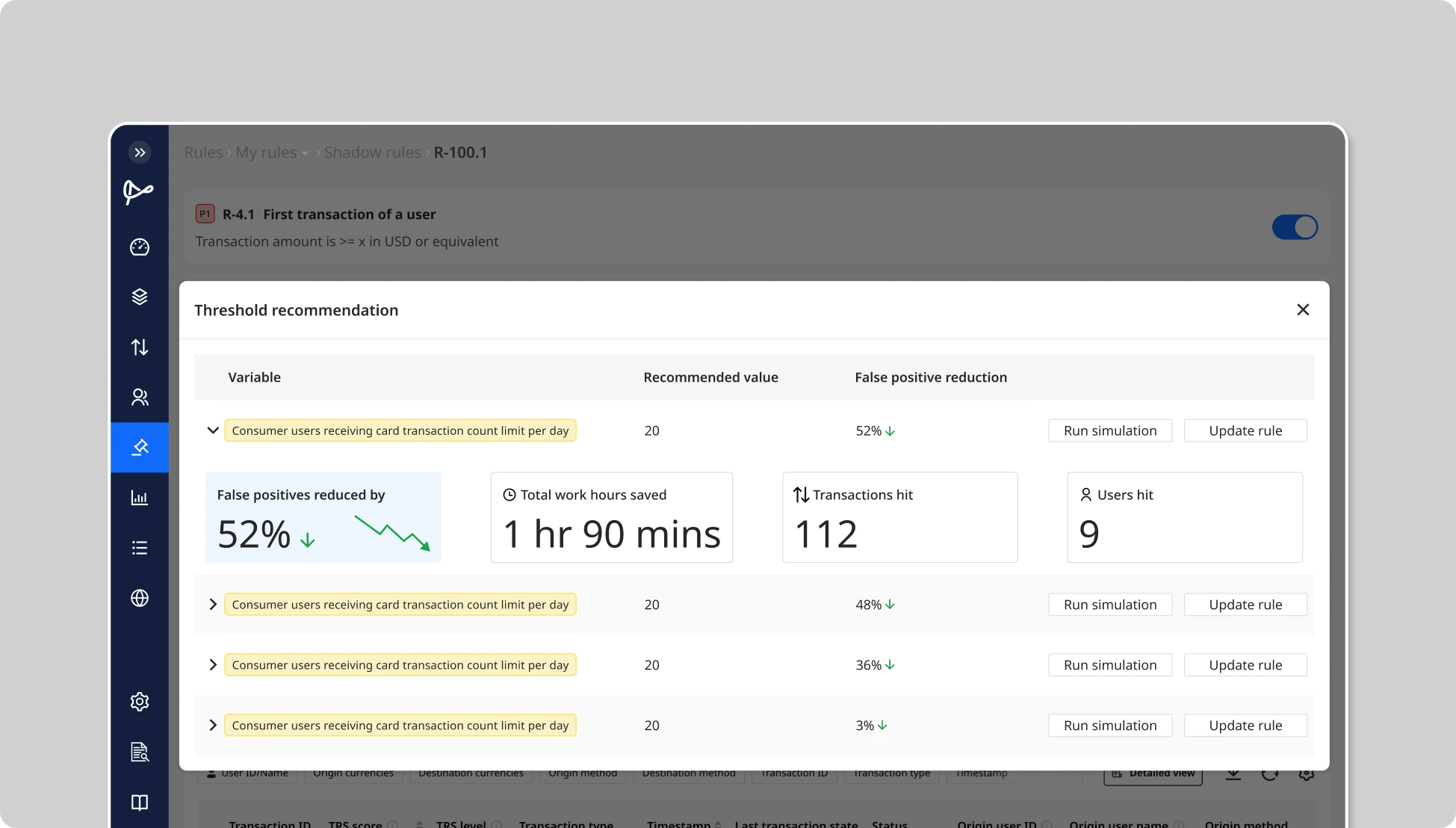
AI-Based Threshold Tuning:
One of Flagright’s capabilities is rule threshold recommendations. The system will examine each rule’s performance statistics, such as its false-positive rate, how many transactions trigger it, how many unique users trigger it, etc., and use machine learning to propose an optimal threshold setting. For example, if a rule is catching too many low-value transactions that end up false, the AI might suggest raising the amount threshold from $500 to $800 to cut out noise, or narrowing the time window of a velocity rule from 24 hours to 12 hours. These recommendations are data-driven: the AI crunches historical data and finds the inflection point where the rule would still catch known suspicious cases but would have generated far fewer false alerts. By leveraging these suggestions, teams can accelerate their tuning work, you don’t always have to manually trial different values, because the system has done the analysis for you. Of course, any AI-suggested threshold change can (and should) be validated via the same simulation and shadow process above before full adoption, but it gives you a strong starting point.
AI-Identified New Rules or Logic:
Beyond thresholds, Flagright’s AI can recommend entirely new rules or scenario tweaks based on patterns it detects in your data and emerging typologies. These rule recommendations consider a wide array of factors, your transaction data trends, the nature of your customer base and business model, geographic risk factors, historical alerts and how they were resolved (which alerts turned into SARs vs. false alarms), and even external knowledge like recent regulatory changes or common threat patterns seen across the industry. For instance, the AI might notice that a certain pattern of small credits followed by a large withdrawal has been associated with suspicious behavior elsewhere and suggest a rule to capture that pattern. Or it may observe that a particular customer segment consistently triggers a rule due to some benign reason and suggest splitting the rule logic to treat that segment differently. Uniquely, Flagright’s platform even bases some recommendations on global insights, it knows what the most frequently used effective rules are across its client base in different regions, and can hint if your program is missing a scenario that peers commonly use.
How to Leverage AI Recommendations:
When the platform provides a recommendation, it typically comes with context, e.g., “Rule X has a 85% false-positive rate. Consider raising threshold from $1,000 to $1,500” or “Transactions just under your current threshold are causing many false alerts; AI suggests adjusting the rule or adding a condition for customer risk tier.” Compliance teams should review these suggestions in their regular rule review meetings. Each recommendation is essentially a hypothesis by the AI on how to improve detection efficiency. Treat it as a valuable input: you can then test the AI’s suggestion via simulation (for a threshold change) or run a new suggested rule in shadow mode to see if it yields benefit. Often, the AI might surface ideas that weren’t obvious just by manual analysis. For example, it may highlight that “Rule Y rarely fires, but peer institutions dealing with crypto transactions often monitor XYZ pattern which you haven’t implemented.” This could prompt you to adopt a new rule to cover a blind spot, again starting in shadow mode.
Flagright’s AI recommendations are built on what’s happening in your environment and the broader threat landscape, so they effectively help you continuously calibrate your monitoring to both your own data and industry typologies. They also ensure you’re keeping up with evolving risks: if new regulatory guidance comes out or a new fraud scheme is trending, the system can nudge you to update your rules accordingly. By incorporating AI into your tuning cycle, you move toward a more proactive stance, instead of waiting until a rule performs poorly, the AI might prompt tuning before the performance degrades or before a new risk goes unaddressed.
In summary, AI-driven rule and threshold recommendations act as a smart compass for your tuning efforts. They suggest where to tighten or loosen rules and where to add new scenarios, based on a rich analysis of data and patterns that would be hard for humans to sift through manually. When combined with your team’s expertise, these recommendations can significantly speed up the optimization process and ensure you’re not missing subtle opportunities to improve. Always remember to validate AI suggestions (they are recommendations, not automatic changes), but over time you’ll likely find the AI is right more often than not, guiding you to a finely tuned, dynamically adapting rule set.
Achieving Precision and Continuous Improvement
By following the above approach, compliance teams can create a virtuous cycle of continuous improvement in their transaction monitoring program. Each component, analytics, simulation, shadow testing, and AI insights – plays a critical role:
- Analytics help you pinpoint where the problems are (which rules are too noisy or too quiet).
- Simulation lets you experiment with solutions in a safe sandbox, learning from historical patterns to calibrate rules optimally.
- Shadow rules provide a real-world trial run, ensuring that any change works as intended in live conditions without disrupting operations or flooding analysts.
- AI recommendations add an intelligent layer of guidance, flagging tuning opportunities you might miss and keeping your detection logic aligned with actual risk data and evolving typologies.
This cycle repeats continuously, meaning your monitoring rules are never static. They are living controls that adapt with your business and emerging threats. The benefits of this continuous tuning approach are profound: you minimize false positives (freeing your team from investigating piles of innocuous alerts), improve true detection rates (catching more suspicious behavior by focusing on meaningful patterns), and avoid disruptive missteps (no more rule changes causing chaos, since everything is tested and vetted in advance).
Crucially, this ongoing optimization also satisfies regulatory expectations. Regulators are increasingly looking for institutions to demonstrate a risk-based, responsive AML program. Being able to show that you regularly tune your scenarios (and having the data to prove it, e.g. “we lowered our false positive rate from 85% to 50% over 6 months by refining thresholds”) underscores that your compliance program is effective and improving. It also ensures you are quicker to adapt to new forms of financial crime, which means less chance of a major incident going undetected.
In practice, organizations that embrace these techniques have reported dramatic improvements. For example, by using Flagright’s simulation and shadow capabilities, some firms cut their false positives by over 90%, vastly reducing wasted effort. Another fintech saw its false-positive rate drop from ~99% to 15% after a series of targeted rule optimizations, while simultaneously speeding up investigations by 50% thanks to having fewer, more relevant alerts to handle. These are the types of outcomes that transform a compliance program from a check-the-box cost center into a strategic advantage for the company.
Conclusion: Tuning transaction monitoring rules is an ongoing journey, not a one-time task. By leveraging Flagright’s rule simulation, shadow rules, and AI-driven recommendations, compliance teams can confidently fine-tune their detection rules over time without fear of error or service interruption. The process outlined above, identify, test, trial, monitor, and repeat, creates a cycle where your AML controls get progressively smarter and more efficient. The end result is a high-precision monitoring system that catches the bad actors while minimizing friction for everyone else, all maintained through a proactive, data-driven workflow. Continuous tuning ensures your defenses keep pace with evolving risks, regulatory demands, and business growth. With the right tools and practices in place, you’ll never have to settle for 90% false positives or month-long rule deployments again. Instead, you’ll cultivate an agile compliance program that delivers safe, effective monitoring, protecting your institution while empowering it to operate smoothly.




